Every company is a data company, whether it’s Google, Meta, or Amazon. Every MNC and startup is ready to pay millions of dollars just to acquire more data, protect the integrity of their data, and derive business strategies from it. Google Cloud has the most advanced data engineering and analysis tools to date. Clients often migrate to Google Cloud to leverage industry leading tools like BigQuery.
Before making business decisions from data, you should be very comfortable with the storage options that Google Cloud offers. To see a detailed overview of storage options, head over to the Google Cloud Documentation.
Pass The First Time—Guaranteed
If you don’t pass the Google Cloud Professional Data Engineer exam the first time, we’ll pay your retest fee.
See details
Types of storage in Google Cloud
Object Storage
In this type of storage, every item is considered an object. You can store anything in it, whether it's an image, a video, or a csv file. The service that supports object storage in Google Cloud is Google Cloud Storage. The Buckets resource offered as a part of Google Cloud Storage is serverless by build, utilizes a pay-as-you-go model, and offers advanced features like Lifecycle and Retention Policy.
Instance Storage

This option is also known as Block Storage. Persistent disks (PDs) are located independently from your virtual machine instances. Therefore, you can detach or move persistent disks to keep your data even after you delete your instances. The major use of persistent disks is to attach them to instances. PDs are advantageous because they are serverless, easy to attach, and have automatic security. As of now, Google Cloud supports four types of persistent disks: Balanced PD, Extreme PD, SSD PD, and Standard PD.
Database Storage
Google Cloud offers a range of options for obtaining and storing various types of data. You can use Cloud Firestore and Cloud BigTable for storing No-SQL Data, and Cloud SQL and Cloud Spanner for OLTP workloads. Furthermore, all these services come with advantages like serverless, autoscaling, cross-region replication, a pay-as-you-go model, and much more. The last option is BigQuery, which isn’t a storage option at all, but is instead used for data analysis and warehousing.
Storage features to keep in mind:
- Availability: This is the criteria for accessing a particular database or entry at a particular point in time. All databases need to be highly available so the company doesn't lose money, even when one of its databases is down. In order to achieve this, use Read Replicas in multiple zones and regions, as well as cross-region replicas.
- Durability: All companies want their data to be highly durable. This just means the data is consistent and in the same original form as it was during the time of commit. Durability is the key component for all Atomicity, Consistency, Isolation and Durability (ACID) transactions.
- Redundancy: Along with availability and durability, the data must be highly redundant. Data must be stored at multiple locations in order to increase consistency and protect it from any data center failure or natural disaster. In Google Cloud, you can store data at regional, dual-regional, or multi-regional locations.
- Frequency of data accessed: We need to be well aware of the frequency of data that is going to be accessed, as querying and storing data comes at a cost. Google Cloud offers a wide range of storage options for storing unstructured data (coldline, nearline, archive, standard) and each option comes with a dynamic cost.
- Security of data: Along with storing data, you need to make sure it’s secure as well. All storage services use Google Managed encryption by default, but if you want to go with more advanced services, you can use Data Loss Prevention (DLP) API to redact or mask personally identifiable information (PII), or Customer Supplied Keys and Key Management System for advanced key management.
Next, let’s learn about the major types of data. With this information, you will be able to learn how to segregate an entire dataset into a predefined data type, use the right storage service, and later on derive key decisions from it.
Types of Data
Structured Data
This is a predefined data type, which means that before ingesting data you need to define the key parameters of the data, and it is stored in rows and columns. For example, if you wanted to create an employee database for your organization, you would need to define the employee name, employee ID, address, and other details. SQL is often used to maintain such databases. The advantages of using structured data are faster access, ease in scaling, and data warehousing. In general, online transactions and SQL Databases are categorized as this data type.
Unstructured Data
This is the most common type of data; around 70% to 80% of generated data falls under this category. Unstructured or unorganized data doesn’t follow a particular schema or order. Unlike structured data, you can’t use rows and columns to store information. We generally store this type of data in object storage (i.e., each entity is separately stored and accessed through keys or identifiers.) Some common examples of this type of data are videos and pictures. The major advantage of unstructured data is that, as they are schemaless, the data is portable and supports even structured data.
Semi-Structured Data
This category is a mixture of the structured and unstructured data format. The data stored in this format is neither row nor column based, nor object based. You should go with this data format when you figure out that your data has some common properties but that those properties are not fixed (e.g., if you are looking for a flexible schema.) Real life examples are XML files, zip files, and emails.
Once you have categorized your data, you'll need to find a suitable storage type.
Types of Relational Databases in Google Cloud
CloudSQL

CloudSQL is a cloud-based solution for MySQL, PostgreSQL, and SQL Server. It is one of the OLTP (Online Transaction Processing) databases provided by Google Cloud, and it supports ACID properties. With CloudSQL, you can create an instance of your desired machine type, store it, and create a public or private instance. You can even create a read replica with high availability and durability.
Note: CloudSQL is not a global service. It also supports advanced features like data backups, accidental deletion, and maintenance windows.
Cloud Spanner
This is also an ACID supported database. The major advantage of choosing Cloud Spanner is that it is a fully managed, globally distributed database by design. Furthermore, Google Cloud provides an SLA of 99.999%, and it can scale up to a whopping 2TB of data per node. Just choose the location of your database (region or multi-region), adjust the number of processing units or nodes (1 node = 1000 processing units), define the schema, and enter the data. It’s that easy to use Cloud Spanner!
Types of NoSQL Databases in Google Cloud
Cloud Firestore & Datastore

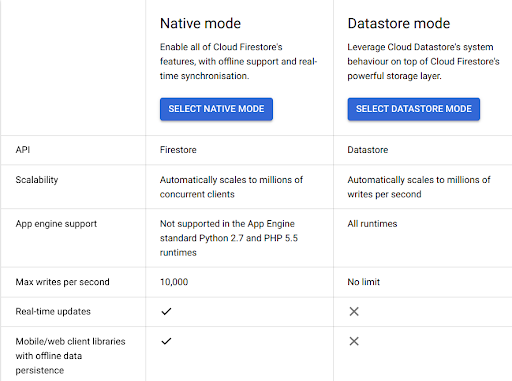
Cloud Firestore is a NoSQL cloud-based database solution, also known as a document database. Choose this type of storage when the schema isn’t fixed or the data has different attributes. Currently it supports two modes, namely native mode and datastore mode.
Note: Once you pick a mode, you won't be able to change it. For more differences between the two modes, you can refer to the table below.
BigTable

BigTable is a wide-column, petabyte-scale managed database. Because it is built using a wide-column database, it comes with advantages like faster speed of querying and flexibility in schema appended by the pros of Cloud. Just like primary keys in relational databases, we use row keys in BigTable. Organizations generally use BigTable when they have to deal with large data streams like IOT sensors.
Note: Be very careful when designing the row keys for BigTable.
Now that you've reviewed data segregation and data storage in Google Cloud, let’s explore data analysis.
BigQuery

BigQuery is one of the industry leading OLAP (Online Analytics Processing) tools currently on the market. It is a fully managed, petabyte-scale, and cost-effective analytics data warehouse that allows you to run analytics over vast amounts of data in near real time. You don’t have to build a team to manage the storage, compute, and DR patterns. Google Cloud will take care of all of that for you.
BigQuery is often confused with an OLTP database solution. BigQuery is not meant for the same purpose as OLTP. The sole purpose of including BigQuery in your architecture should be for data analysis and data warehousing.
BigQuery ML is a subset of BigQuery where you can create machine learning models by using SQL queries. BigQuery Omni is a service that is widely used by hybrid-believers. It is used to run BigQuery on the data stored in third-party services like Amazon S3.
What is a schema?
Schema is the blueprint of your entire database. It defines the number of attributes and the relationship between the attributes. In BigQuery, you can either define your own schema or you can use the auto-detect feature providing you hassle-free analysis of your data.
What are datasets?
Datasets are high level entities that store and manage your data for analysis. You need to have at least 1 dataset in a project in order to start working with BigQuery. Furthermore, there are two types of datasets: Public and Private. Datasets store the data in tables that are used for analysis. Datasets can be regional or multi-regional.
What are tables?
A BigQuery table contains individual records organized in rows. Each record is composed of columns, also called fields. Every table is defined by a schema that describes the column names, data types, and other information. You can specify the schema of a table when it is created, or you can create a table without a schema.
Language needed to run BigQuere queries:
As of now, BigQuery supports two types of query language: Standard SQL (ANSI compliant) and the Legacy SQL (may deprecate soon).
What are federated queries?
Federated queries are very beneficial when you have a Cloud SQL instance running and you want to perform some queries in real-time. To leverage, you create a query with the function EXTERNAL_QUERY(). The condition for using federated queries is that it requires a publicly accessible Cloud SQL instance. Learn more about federated queries here.
What are authorized views?
An authorized view lets you share query results with particular users and groups without giving them access to the underlying tables.
Other Data Analytics Tools
- Dataproc: This tool is a managed cloud-based solution for Apache Hadoop, Apache Spark, Apache Flink, Presto, and over 30 open source tools and frameworks. It is highly utilized in data lakes and ETL Pipelines.
- Dataflow: This is a managed, horizontal, scalable service built on top of Apache Beam Runner. Use this service when you want to create task batches and stream processing tasks.
- Composer: This is a managed service for Apache Airflow. It is often used in hybrid cloud to unify a cloud environment.
Tutorial: How to Use BigQuery
Follow these step-by-step instructions to start using Google's BigQuery for data analysis.
1. Log into your Google Cloud Account.
2. Search for BigQuery in the search bar and select it.

3. For this tutorial we will be using a public dataset. Click on add data to add a full, publicly available dataset.

4. From the variety of options, select public datasets.
5. Select the Covid-19 Public Datasets. These contain public data about Covid-19 cases, countries, and other key metrics.
6. In order to use this dataset, you need to make a copy of it.
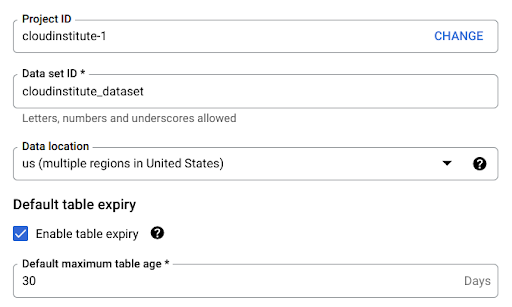
7. Choose your project ID, a unique dataset ID, and the data location. You can even enable the table expiration period if you’d like. Note: You may need to enable some APIs during this process.
8. We have successfully made a copy of the database. In order to query the dataset, select the table with the name covid19_open_data and click on Query.

9. Let’s do some analysis on the data. Enter the query as written below.
SELECT place_id ,wikidata_id , country_code FROM `<PROJECT-ID>.<DATASET-ID>.covid19_open_data` WHERE location_key='US' LIMIT 100
10. One of the most impressive features of BigQuery is that, after you enter a valid query, it checks and returns the number of bytes that will be scanned in order to run the desired output. Note: In BigQuery, you are charged according to the number of bytes scanned.
![]()
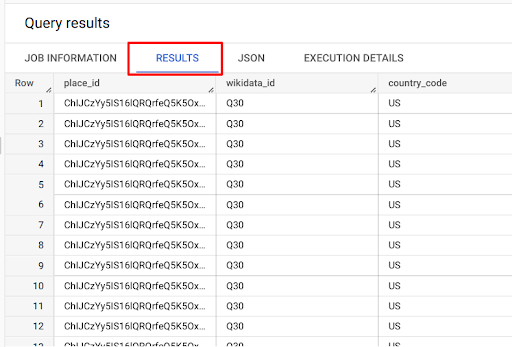
11. You can see the output of the query in the results tab.
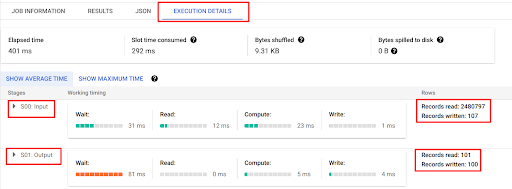
12. You can look at the stages, timing, and row reads and writes of the job in the execution details tab.
13. You can run the sample queries like below and play around with the dataset.
SELECT place_id, count(*) as ci FROM `<PROJECT-ID>.<DATASET-ID>.covid19_open_data` WHERE location_key='US' GROUP BY place_id LIMIT 100
SELECT population ,debt_relief, population_age_20_29 FROM `cloudinstitute-1.cloudinstitute_dataset.covid19_open_data` WHERE debt_relief=1 ORDER BY population DESC LIMIT 100
14. After running any query, you can even save the query and share it with your teammates.
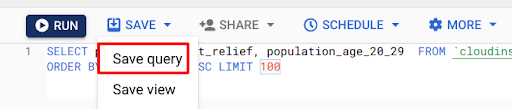
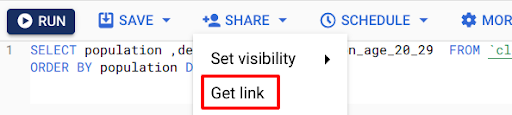
15. Google Cloud offers a variety of options when it comes to your queries, like saving your output in multiple formats and even visualizing the data using tools like Data Studio.

16. We can even work with BigQuery using the bq CLI tool. For the rest of the tutorial, we will be using the cloud shell. Click on the terminal icon to enable it.

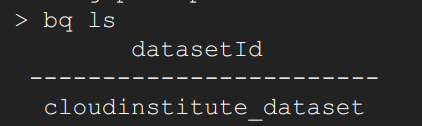
17. Use the bq ls command to list all the datasets in the current project.
18. Let’s create another dataset using the bq mk cloudinstitute_cli_dataset command.

19. Now perform some queries in the dataset we created using the console. Note: You can use the –dry_run parameter, which will tell you the number of bytes the process will need to scan in order to deliver the desired output.
bq query --use_legacy_sql=false --dry_run 'SELECT place_id , country_code FROM `<PROJECT-ID>.<DATASET-ID>.covid19_open_data` LIMIT 100'
20. It’s time to delete the created datasets using the bq rm <DATASET-ID> command to delete any dataset. If you want to delete the tables inside the dataset as well, use the -r flag.
21. Use the bq ls command again to make sure that there is no dataset present. Note: Delete the created resources as they may incur costs.
Google Sheets and BigQuery Experiment
Now let's connect Google Sheets with BigQuery in the following steps.
1. Create a new spreadsheet or open any existing sheet from Google Sheets.
2. Under the data tab, click on data connectors and select BigQuery as the connector.
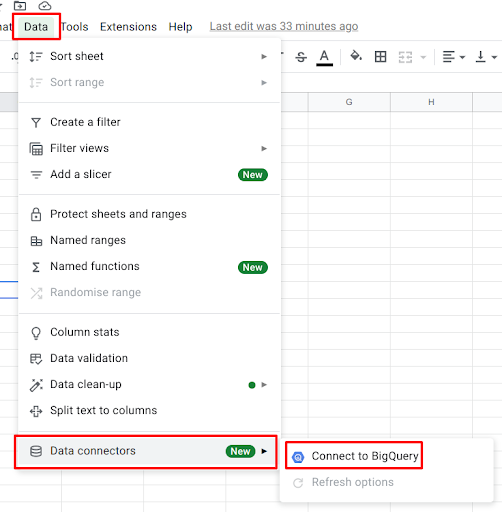
3. As soon as you select BigQuery as the connector, a pop-up window will open showing all the Google Cloud projects connected to your Gmail ID. Note: Make sure to create a dataset and a table in BigQuery, either through the console or the CLI before moving to the next step.
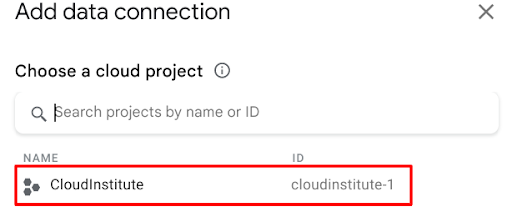
4. Click on connect and run your queries.

You can head over to this Developer Cheat Sheet developed by Google Cloud for a quick recap about the services.
Ready to start earning Google Cloud certifications? We’ll give you a coach and help you pass the exam the first time—guaranteed.